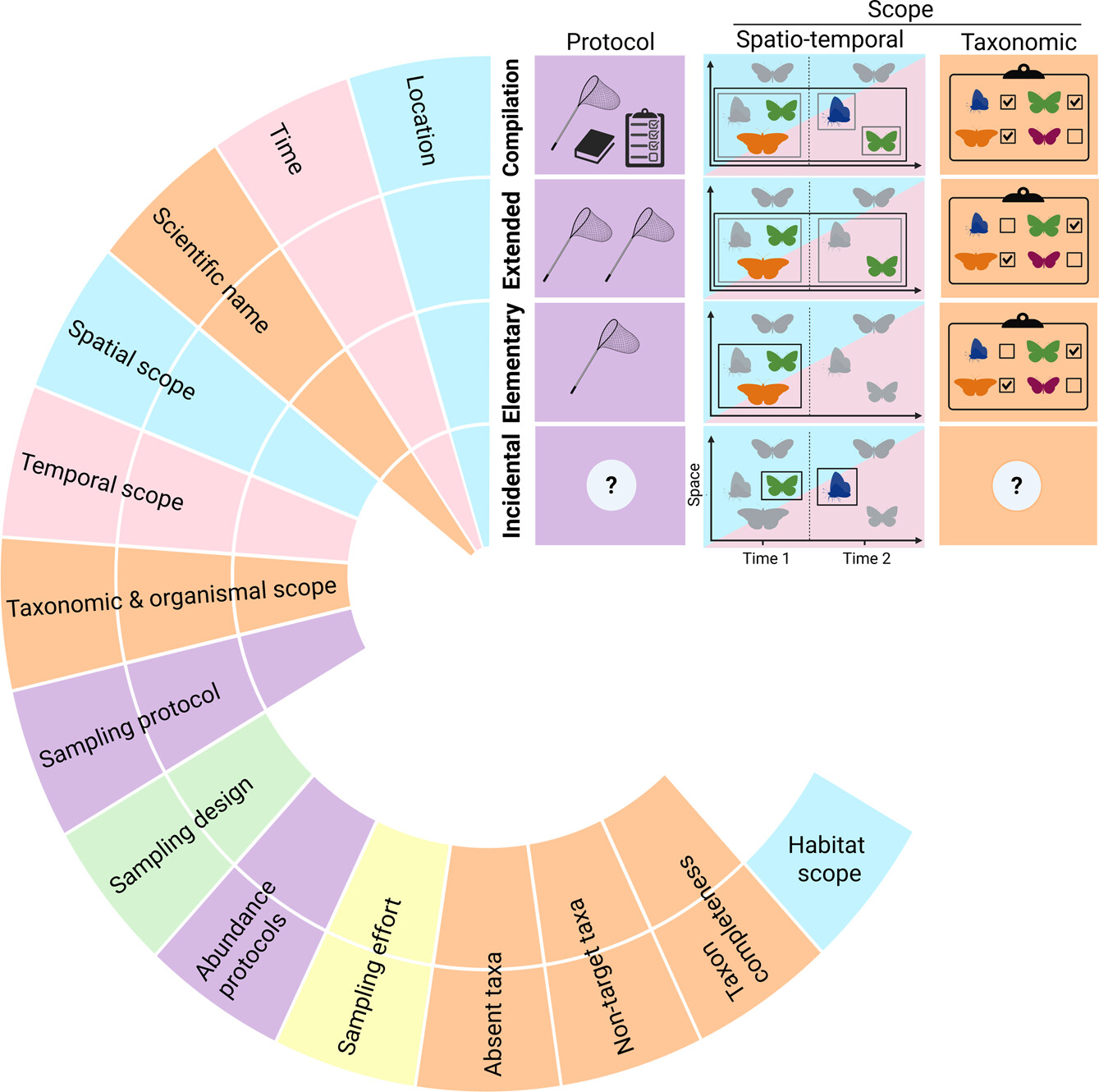
New approach to species distribution modeling boosts predictions for 98 hummingbird species—especially those most at risk
A lot of math goes into developing a model to predict species distributions, and while a lot of data is also helpful, it’s often not attainable, especially for many rare and vulnerable species. Part of the problem is that this species data exists in different forms that aren’t compatible in conventional models, so the conventional approach is potentially missing out on a fuller base of data – an issue that has led some researchers to develop new ways of making the most out of all available species data.
In a new paper published this month in Diversity & Distributions, researchers showed that integrating different data types into species distribution models improved prediction accuracy for species of particular conservation interest, namely narrow-ranged and data-limited species. The work was led by Jussi Mäkinen, a Senior Research Scientist at the Finnish Environment Institute and former postdoc at the Biodiversity and Global Change (BGC) Center, alongside BGC Center Associate Research Scientist Jeremy Cohen and Director Walter Jetz.

Species distribution models (SDMs) – programmatic methods of estimating where species live in the environment by relating observations of the species with climate and habitat information – are an essential element in a conservationist’s toolbox that support more informed decision making for species management and preservation.
A conventional SDM uses one of two observation types: presence-only or presence-absence. Most SDMs run on the former, which the researchers describe as opportunistic data points, or coincidental observations of a species. For example, if you post pictures of species to iNaturalist, you’re contributing to a presence-only dataset. This is valuable data, but it can be subject to spatial biases – for example, there are more data points in parks frequented by visitors than in remote areas, and it cannot be assumed from presence-only data that the species isn’t found in areas that don’t have any data points.
SDMs can also be built on presence-absence data. This is data gathered in a more structured way: a given area is surveyed for a specific species or species group with a documented amount of effort, so researchers can estimate the likelihood that the species is absent. This kind of data is something you might get from eBird, where users can confirm if they are recording all the birds they observe in the field and report additional information on survey protocol and effort, so that any missing species can be inferred as absent. This information also helps the SDM account for spatial biases in the data.
For an SDM to deliver an accurate estimation, however, it needs enough data – something a lot of species are unfortunately lacking. For many situations, there isn’t enough presence-only or presence-absence data available for a species. So, Mäkinen developed a third option: both datasets integrated into a single SDM.
In their new paper, Mäkinen and co-authors investigate the utility of these integrated SDMs to overcome limitations of data scarcity and increase the accuracy of estimated species distributions.
Some previous studies had tested types of integrated SDMs, but only with small groups of species and over restricted spatial extents. This new paper undertakes the investigation at the broadest scale yet – across all of Central and South America – and for a large and diverse group of species – hummingbirds.
“Hummingbird species have different levels of niche specialization and span a wide spectrum of range sizes and survey densities,” said Mäkinen. This variation, according to Mäkinen, makes them an ideal study group to test how the integrated models perform for species across range sizes and dataset sizes.
For 98 species, the researchers ran three different models – a presence-only SDM using data points from GBIF, a presence-absence SDM using data points from eBird, and an integrated SDM using both datasets – and compared the predictive accuracy of the models in scenarios where species observations only partially covered the species range. Such scenarios represent true use cases of SDMs for most species. For about half of the study species which had sufficient data, they additionally tested whether the integrated models could achieve similar outcomes with different amounts of data.
Mäkinen and coauthors found that on average, the integrated models performed equally well or better than the two conventional models, and the increase in prediction accuracy of the integrated model was especially pronounced for data deficient and narrow ranged species.
For the experimentally data-thinned species, the integrated models consistently performed better than the presence-only models, even when only a small number of presence-only points were combined with the presence-absence data.
The researchers speculated that the combination of presence-only and presence-absence data boosted model performance in two key ways: first, the addition of presence-only points, when compared to presence-absence models, increases the spatial coverage of data points, thereby helping the model derive a more accurate association between the points and their surrounding environmental conditions; second, the addition of presence-absence points, when compared to presence-only models, allows the model to make use of the information on survey effort, thereby improving spatial interpolation between the data points.
The integrated model “accounts for the survey protocol of presence-absence data, such as number of surveyors, distance covered by surveying and time spent for surveying,” said Mäkinen. “Such information is not available for presence-only data, but with the joint use of both data sets, we can estimate additional spatial clustering of presence-only data that is not explained by the ecological and spatial constraints of the species distribution,” i.e., clustering of data points around high-traffic areas like cities, roads, and parks.
According to the researchers, these results suggest that applying data integration techniques for species distribution modeling can support more accurate conservation assessments by generating more accurate predictions of species ranges.
As for next steps, Mäkinen sees potential in utilizing integrated SDMs with another strategy in the species distribution modeling sphere: borrowing strength, or modeling multiple species together. “Integrated models could be fitted jointly for multiple species to borrow strength between them,” he said, which “allows us to include functional and phylogenetic dependencies between species to strengthen even more the analysis of data deficient species.” Presence-absence data isn’t generally as readily available for other species groups as it is for birds, but many national and international species monitoring programs, such as European butterfly monitoring scheme or European mammal monitoring, collect structured survey data that could be utilized in integrated SDMs.
“I am currently studying range dynamics over time using integrated models and plan to use the integrated and multi-species approaches to study the efficiency of protected areas for population viability,” Mäkinen said. “These analyses cover species with different ecological status, for example common, rare, native, invasive and data deficient species.”